목차
1. 분류
특성을 보고 해당 데이터를 적절한 카테고리에 올바르게 매핑시키는 것
대표적인 지도학습 기법
1) 이진 클래스분류
ex) 스팸메일 vs. 정상메일

2) 다중 클래스 분류
ex) 숫자 인식

3) 다중 레이블 분류

2. 베이즈 정리
- 조건부 확률: 어떤 사건이 일어났다는 전제 하에 다른 사건이 일어날 확률
베이즈정리
조건부확률 계산 식.
기존의 믿음으로 대표되는 P(A), 새로운 증거 P(B)를 보고 기존의 믿음을 더 알맞게 업데이트하는 식임.
사전확률로부터 사후확률을 구할 수 있다!
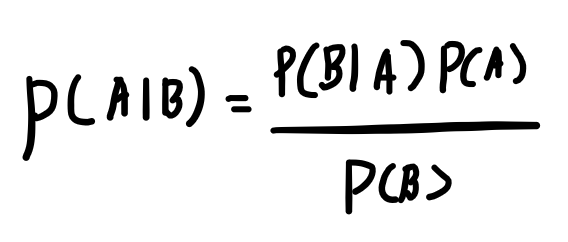

3. Naïve Bayes (나이브베이즈 분류기)
m개의 특성을 지닌 샘플 데이터 x가 주어졌을 때, 나이브 베이즈의 목표는 이 샘플 데이터가 k개의 클래스($y_{1}$~$y_{k}$) 중 하나에 속할 확률 결정
$P(y_{k} | \overrightarrow{x})$ or $P(y_{k} | x_{1},x_{2},...,x_{m})$
$$argmax_{y_{k}}P(y_{k} | \overrightarrow{x} )$$

모든 특성들은 서로 독립(조건부 독립)이라는 가정을 두면 조합에 대한 확률이 아니라 각 개별 특성에 대한 확률의 문제로 바뀐다. => 상대적으로 적은 샘플데이터로 학습 가능
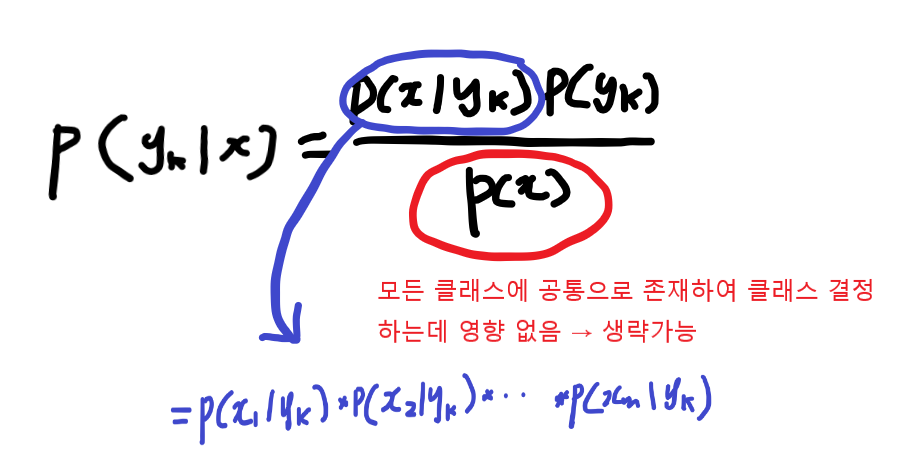
Likelihood 값(파란부분) 구하기
- 스무딩: 값이 0이 되지 않도록 하는 방법 => 라플라스 스무딩: 한번씩은 출연했다고 가정하여 likelihood 계산
나이브베이즈동작예시: (분류) 스팸일 경우, 아닐경우의 확률을 계산 (단어 출연 빈도를 가지고)
ln() 사용
likelihood가 0~1사이의 값을 가져서 계속 곱하다보면 매우 작은 값을 가지게 된다(m이 클때).
이를 자연로그 취해서 곱셈이 아닌 덧셈의 방식으로 바꿔 계산하면 문제를 해소할 수 있다고 한다.
'AI&ML > Machine Learning' 카테고리의 다른 글
| [ML] 04. Decision Tree (1) | 2024.01.12 |
|---|---|
| [ML] 03. Evaluation (0) | 2024.01.12 |
| [ML] 02. Text Data (0) | 2024.01.12 |
| [ML] 00. Overview (0) | 2024.01.06 |
| [ML] 목차 (1) | 2023.12.27 |